PCI Configuration Space
ハイパーバイザの作り方~ちゃんと理解する仮想化技術~ 第15回 PCIパススルーその1「PCIパススルーとIOMMU」
前回・前々回は、総集編として2回にわたり仮想化システムの全体像をふりかえりました。
今回は、PCIパススルーについて解説していきます。
PCIパススルーの解説を行う前に、まずは簡単にPCIについておさらいしましょう。
PCIデバイスはBus Number・Device Numberで一意に識別され、1つのデバイスが複数の機能を有する場合はFunction Numberで個々の機能が一意に識別されます。
Linuxで"lspci -nn"を実行したときに出力の左端に表示される「aa:bb:c」のうち、aaがBus Number、bbがDevice Number、cがFunction Numberにあたります(リスト1)。
さらに、そのデバイスがどこのメーカーのどの機種であるかという情報はVendor ID・Device IDで表され、この情報によってOSはロードするドライバを選びます。 Linuxでlspci -nnを実行したときに出力の右端に表示される「dddd:eeee」のうち、ddddがVendor ID、eeeeがDevice IDにあたります。
$ lspci -nn|grep IDE
00:1f.2 IDE interface [0101]: Intel Corporation 82801JI (ICH10 Family) 4 port SA
TA IDE Controller #1 [8086:3a20]
00:1f.5 IDE interface [0101]: Intel Corporation 82801JI (ICH10 Family) 2 port SA
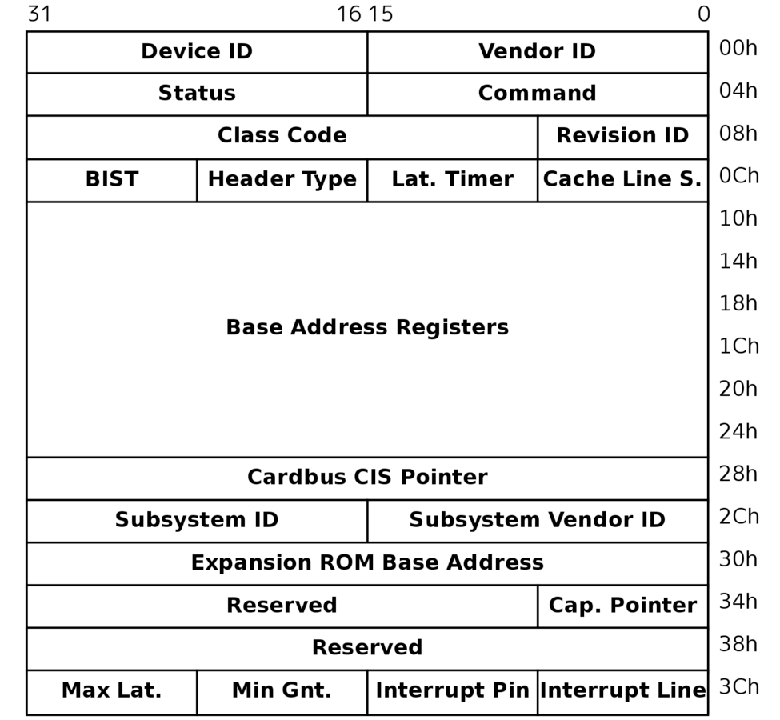
TA IDE Controller #2 [8086:3a26]これらのデバイスはPCI Configuration Space、PCI I/O Space、PCI Memory Spaceの3つのメモリ空間を持ちます。 PCI Configuration Spaceはデバイスがどこのメーカーのどの機種であるかを示すVendor ID・Device IDや、PCI I/O Space・PCI Memory Spaceのマップ先アドレスを示すBase Address Register、MSI割り込みの設定情報など、デバイスの初期化とドライバのロードに必要な情報を多数含んでいます。
PCI Configuration Spaceにアクセスするには、次のような手順を実施する必要があります。
OSはPCIデバイス初期化時に、Bus Number・Device Numberをイテレートして順に PCI Configuration SpaceのVendor ID・Device IDを参照することで、コンピュータに接続されている PCIデバイスを検出できます。
PCI I/O SpaceはI/O空間にマップされており(図2)、おもにデバイスのハードウェアレジスタをマップするなどの用途に使われているようです3。
PCI Memory Spaceは物理アドレス空間にマップされており、ビデオメモリなど大きなメモリ領域を必要とする用途に使われているようです4。
どちらの領域もマップ先はPCI Configuration SpaceのBase Address Registerを参照して取得する必要があります。
| bit | name |
|---|---|
| 31 | Enable Bit |
| 30-24 | Reserved |
| 23-16 | Bus Number |
| 15-11 | Device Number |
| 10-8 | Function Number |
| 7-2 | Register offset |
PCI Configuration Space
82583V GbE Controllerのパケット送信機能
PCIデバイスが持つメモリ空間に対して読み書きを行うことで、OS上のデバイスドライバとデバイスの間でデータをやりとりできます。 具体的には、I/O空間に対してならin/out命令を発行、物理アドレス空間ならアドレスに対してmemcpy()のような処理を行うことでデータを転送します。 しかしながら、この方法ではブロックデバイスや高速なNICなど、短い時間に大量のデータを転送する用途ではデータ転送を行う度にCPUが占有されてしまい、十分な性能が得られません。 このようなPCIデバイスではDMA機能が使用されます。
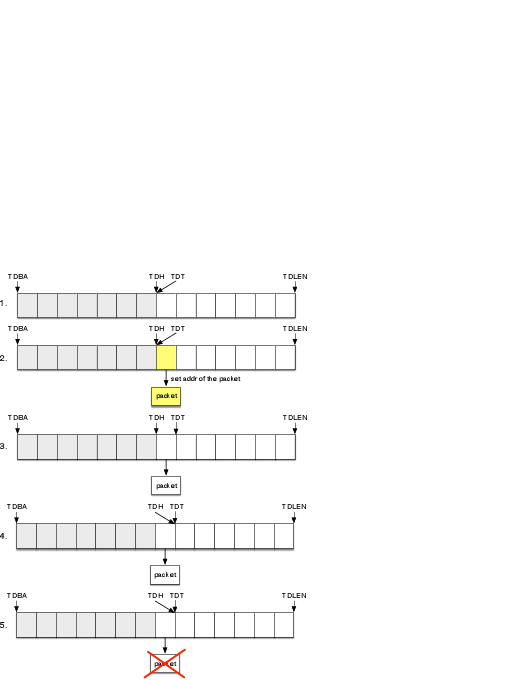
例として、82583V GbE Controller(e1000e)のパケット送信機能におけるDMAの使われ方を見てみましょう。 図3に82583Vの送信用リングバッファと4種類のハードウェアレジスタ(TDBA、TDLEN、TDH、TDT)の関係を示しました。
TDBAはリングバッファの先頭アドレスを指します。 TDLENはリングバッファ長を示します。 TDHはNICがリングバッファのどこまで送信完了したかを示します。 TDTはドライバがリングバッファのどこまでパケットを積んだかを示します。
次にパケット送信の手順を示します。 手順で用いる番号は図3の番号に対応しています。
上述の例では話をわかりやすくするため、登場するパケットは1つだけにしましたが、実際にはNICの送信状況にかかわらずドライバはどんどんリングバッファへパケットを積んでいきます5。 NICは順にパケットをDMA転送して、送信が完了したら送信完了割り込みを行います。 ドライバがTDTへ書き込んでからNICが送信を完了するまでの間、OSは送信完了を待つ必要はありません。 この間、OSはほかの処理にCPUの時間を使えます。 送信に使ったパケットバッファを片付けるために、OSはNICからの送信完了割り込みを使います。
ゲストOSによるCONFIG_ADDRESSレジスタとCONFIG_DATAレジスタへのアクセスをVMExit Reason 30(I/O Instruction)のVMExitを用いてVMMでハンドルします6。
VMMはCONFIG_ADDRESSレジスタに設定されたBus Number・Device Number・Function Numberからどのデバイスへアクセスが来たのかを識別し、パススルー対象デバイス宛てであれば、実デバイスのConfiguration Spaceの指定オフセットへアクセスを行います。 書き込みであればCONFIG_DATAレジスタの値を実デバイスへ書き込み、読み込みであれば実デバイスから読み込んでCONFIG_DATAレジスタから返します。
ゲストOSによるパススルーデバイスのPCI I/O Spaceへのアクセスも、同じくVMExit Reason 30(I/O Instruction)のVMExitを用いてVMMでハンドルします。 このとき対象デバイスが持っているI/Oポートの範囲はPCI Configuration SpaceのBase Address Registerで定義されており、VMMはこの値を記憶しておくことでどのデバイスへのI/O命令であったか判別できます。
VMMはゲストからデバイスのポートへI/O命令を受け、同じポートへI/O命令を発行し結果をゲストに返します。 あるいは、ゲスト側とホスト側でI/Oポートの番号が一致している場合7は、前述の方法をとらずにVMCSのVM-Execution Control FieldsにあるI/O-Bitmapで対象となるポート番号のビットを0に設定することでVMExitを起こさずにPCIデバイスへアクセスできます。
ゲストOSによるPCI Memory Spaceへのアクセスは、ゲストマシンの物理メモリ空間のページ割り当てを設定することで実現します。 本連載の『第3回I/O仮想化「デバイスI/O編」』にて、EPTによるメモリマップドI/Oのハンドリング方法として、デバイスがマップされたアドレスへのアクセスが発生したときにVMExit reason 48(EPT violationで、VMExitさせる方法)を示しました8。
このように無効なページを作ってVMExitさせるのではなく、デバイスがマップされたページを有効なページとして設定9し、実デバイスのメモリマップされたエリアをマップします。 これにより、ゲストOSはVMExitされることなく直接実デバイスのPCI Memory Spaceに対してアクセスできます。
実PCIデバイスからの実割り込みはVMExit reason 1(External Interrupt)を生じさせ、VMMによって10ハンドルされます。 VMMはこの割り込みを処理するためのパススルー専用割り込みハンドラをあらかじめ登録しておく必要があります。 割り込みハンドラはこの割り込みを受け付け、ゲストOSへ割り込みが届いたことを伝えるために、ゲストマシンのLocal APICレジスタを更新します。 そしてVMCSのVM-entry interruption-information fieldへ割り込みをセットしてVMEntryします11。 これにより、VMMで受け取った割り込みがゲストへ伝えられ、ゲストOSが割り込みハンドラを実行できます。
ここまで、PCIメモリ空間や割り込みは一定の手順を踏めばパススルーできるということを示してきましたが、DMAでは1つ困った問題が生じます。
PCIデバイスはDMA時のアドレス指定にホスト物理アドレスを使用します。 通常、物理メモリ領域の全域にアクセスできます。 もちろん、PCIデバイスはデバイスを使用しているOSが仮想化されていることなど知りません。
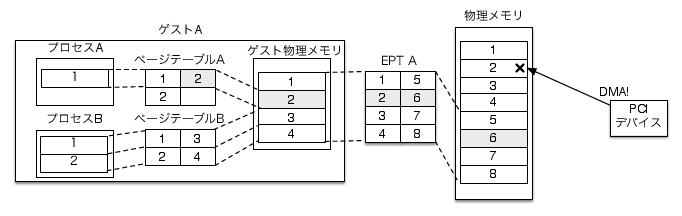
この状態で、図4のゲストA上のドライバがDMA先アドレスとしてゲスト物理ページの2番を指定すると何が起こるでしょうか? PCIデバイスはDMAリクエスト元のOSが仮想化されていることを知らないので、ホスト物理ページの2番へDMA転送を行います。 結果、PCIデバイスはゲストAのメモリ領域の範囲外にデータを書き込んでしまいます。
これにより、別のゲストマシンやVMMのメモリ領域を破壊してしまいます。 かといって、ゲストOSは自分が持つゲスト物理ページとホスト物理ページの対応情報を持っていないので正しいページ番号をドライバに与えられません。 たとえ持っていたとしても、ゲストOSが悪意を持ってゲストマシンに割り当てられている範囲外のページ番号を指定することで他のゲストマシンやVMMのメモリ領域を破壊できるという問題が解決しません。
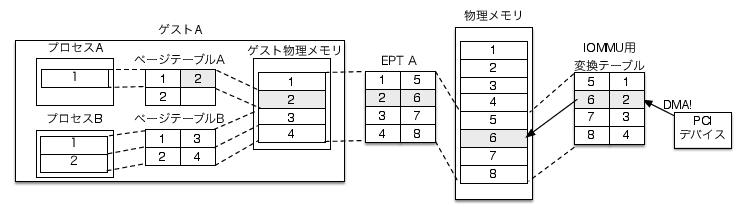
そこで、物理メモリとPCIデバイスの間にMMUのような装置を置きアドレス変換を行う方法が考え出されました。 このような装置をIOMMUと呼びます。
DMA転送時にアドレス変換を行うことで、図4の例ではゲストAのメモリ領域の範囲外へデータを書き込んでしまっていたパススルーデバイスが正しいページへデータを書き込めるようになります(図5)。
Intel VT-dは、このような機能を実現するためにチップセットへ搭載されたIOMMUです。 VT-d対応PCでは、VMMがIOMMUへ変換テーブルを設定してアドレス変換を行い、ゲストマシンへの安全なデバイスパススルーを実現できます。
PCIパススルーでDMA転送時に生じる問題
IOMMUを用いたDMA時のアドレス変換
今回は、PCIのおさらいとPCIパススルーの実現方法、IOMMUについて解説しました。 次回は、Intel VT-dの詳細について解説します。
Copyright (c) 2014 Takuya ASADA. 全ての原稿データ は クリエイティブ・コモンズ 表示 - 継承 4.0 国際 ライセンスの下に提供されています。
PCではCONFIG_ADDRESSレジスタはI/O空間の0xCF8にマップされています。↩
PCではCONFIG_DATAレジスタはI/O空間の0xCFCにマップされています。↩
PCではI/O空間にマップされますが、ほかのアーキテクチャではメモリマップされる場合もあると思われます。↩
必ずしもこのように使い分けられているわけではなく、ハードウェアレジスタのマップにPCI Memory Spaceを使用するデバイスも存在します。↩
ただし、リングバッファが一杯になってしまったら一時的に送信を抑制するなどの措置をとります。↩
詳しくは第3回I/O仮想化「デバイスI/O編」を参照。↩
VMMが独自のBase Address Registerを用意しておらず、実デバイスのものをそのままゲストに見せている場合。↩
シャドーページングのときも同じ要領で設定ができますが、今回は解説を割愛します。↩
Read accessビット・Write accessビットをともに1にします。↩
KVM・BHyVeのようにホストOS上でVMMが動く場合はホストカーネルによって違います。↩
詳しい仮想割り込みのセット方法は第5回I/O仮想化「割り込み編・その2」を参照。↩